
티스토리 뷰
이번 강좌는 MongoDB의 Index에 관한 내용입니다.
Index란?
Index는 MongoDB에서 데이터 쿼리를 더욱 효율적으로 할 수 있게 해줍니다. 인덱스가 없이는, MongoDB는 collection scan – 컬렉션의 데이터를 하나하나 조회 – 방식으로 스캔을 하게 됩니다. 만약 document의 갯수가 매우 많다면, 많은 만큼 속도가 느려지겠죠? 이 부분을 향상시키기 위하여 인덱스를 사용하면 더 적은 횟수의 조회로 원하는 데이터를 찾을 수 있습니다.
Document의 필드(들) 에 index 를 걸면, 데이터의 설정한 키 값을 가지고 document들을 가르키는 포인터값으로 이뤄진 B-Tree를 만듭니다. 여기서 B-Tree는 Balanced Binary search Tree 인데요, B-Tree 에서 Binary Search를 통하여 쿼리 속도를 매우 빠르게 향상 시킬 수 있습니다. Balanced Binary Tree / Binary Search 키워드에 대해선 자료구조를 공부하신 분들이라면 익숙하겠지만 그렇지 않은 분들을 위해 한번 간단하게 원리를 설명해보겠습니다.
만약에 숫자가 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 가 있을 때 이 중에서 14를 찾는다고 한다면, Index가 없을때는 1부터 14까지 쭉 조회를 하여 14를 찾아냅니다.
하지만 Index가 있을땐 다음과 같은 B-Tree를 만듭니다. ( B-Tree가 만들어지는 과정은 생략하겠습니다. )
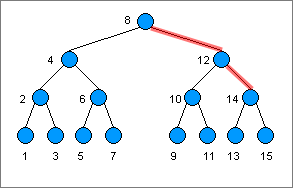
이 트리를 간단하게 설명해드리자면, 특정 값보다 작은 값은 왼쪽에, 큰 값은 오른쪽에 위치하는 규칙을 가지고 있는데요.
이 트리를 사용하여 14를 찾을땐 8 → 12 → 14 이렇게 3번의 조회만에 14를 찾을 수 있게됩니다.
그리고, 순회 알고리즘을 사용하여 가장 낮은값부터 가장 큰 값 까지 매우 효율적으로 정렬도 할 수 있습니다.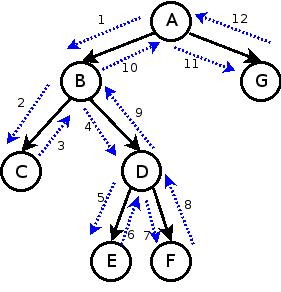
자, 이제 원리를 이해하였다면 MongoDB에서 인덱스를 사용하는 방법을 배워보겠습니다.
Index의 종류
기본 인덱스 _id
모든 MongoDB의 컬렉션은 기본적으로 _id 필드에 인덱스가 존재합니다. 만약에 컬렉션을 만들 때 _id 필드를 따로 지정하지 않으면 mongod드라이버가 자동으로 _id 필드 값을 ObjectId로 설정해줍니다.
_id 인덱스는 unique(유일)하고 이는 MongoDB 클라이언트가 같은 _id 를 가진 문서를 중복적으로 추가하는 것을 방지합니다.
Single(단일) 필드 인덱스
MongoDB 드라이버가 지정하는 _id 인덱스 외에도, 사용자가 지정 할 수 있는 단일 필드 인덱스가 있습니다.
다음 이미지 처럼 score 값으로 정렬 할 수 있지요.

Compound (복합) 필드 인덱스
두개 이상의 필드를 사용하는 인덱스를 복합 인덱스라고 부릅니다. 다음 이미지와 같이 첫번째 필드 (userid)는 오름차순으로, 두번째 필드 (score)는 내림차순으로 정렬 해야 하는 상황이 있을때 사용합니다.

Multikey 인덱스
필드 타입이 배열인 필드에 인덱스를 적용 할 때는 Multikey 인덱스가 사용됩니다. 이 인덱스를 통하여 배열에 특정 값이 포함되어 있는 document를 효율적으로 스캔 할 수 있습니다.
Geospatial(공간적) Index
지도의 좌표와 같은 데이터를 효율적으로 쿼리하기 위해서 (예: 특정 좌표 반경 x 에 해당되는 데이터를 찾을 때) 사용되는 인덱스입니다. 자세한 사항은 매뉴얼을 참고해주세요.
Text 인덱스
텍스트 관련 데이터를 효율적으로 쿼리하기 위한 인덱스입니다. 자세한 사항은 매뉴얼 Text Indexes 을 참고하세요.
해쉬 (hashed) 인덱스
이 인덱스를 사용하면 B Tree가아닌 Hash 자료구조를 사용합니다. Hash는 검색 효율이 B Tree보다 좋지만, 정렬을 하지 않습니다.
인덱스 생성
인덱스를 생성 할 땐, 다음과 같은 createIndex() 메소드를 사용합니다. 파라미터는 인덱스를 적용할 필드를 전달합니다. 값을 1로하면 오름차순으로, -1로 하면 내림차순으로 정렬합니다.
db.COLLECTION.createIndex( { KEY: 1 } )다양한 예제를 통하여 인덱스 생성을 배워보도록 하겠습니다.
예제1 단일 필드 인덱스 생성
db.report.createIndex( { score: 1 } )score 필드에 인덱스를 걸어줍니다.
이 인덱스는 다음과 같은 쿼리를 할 때 효율적으로 실행하게 해줍니다.
db.report.find( { score: 57 } )
db.report.find( { score: { $gt: 60 } } )예제2 복합 필드 인덱스 생성
db.report.createIndex( { age: 1, score: -1} )이렇게 여러 필드를 넣어 인덱스를 생성하면 age를 오름차순으로 정렬한 상태에서 score 는 내림차순으로 정렬합니다.
인덱스 속성
인덱스에 속성을 추가 할 땐 createIndex() 메소드의 두번째 인자에 속성값을 document 타입으로 전달해주면 됩니다.
db.COLLECTION.createIndex( { KEY: 1 }, { PROPERTY: true } )인덱스에 적용 할 수 있는 4가지 속성이 있는데요, 한번 이에 대해 알아보고, 예제를 통해 사용법을 배워보도록 하겠습니다.
Unique (유일함) 속성
_id 필드처럼 컬렉션에 단 한개의 값만 존재 할 수 있는 속성입니다.
예제3 email 인덱스에 unique 속성 적용
db.userinfo.createIndex( { email: 1 }, { unique: true } )unique 속성은 다음처럼 복합 인덱스에도 적용 할 수 있습니다.
예제4 firstName 과 lastName 복합인덱스에 unique 속성 적용
db.userinfo.createIndex( { firstName: 1, lastName: 1 }, { unique: true } )Partial (부분적) 속성
partial 속성은 document의 조건을 정하여 일부 document에만 인덱스를 적용 할 때 사용됩니다.
partial 속성을 사용하면, 필요한 부분에만 인덱싱을 사용하여 저장공간도 아끼고 속도를 더 높일수 있습니다.
예제5 visitors 값이 1000 보다 높은 document에만 name 필드에 인덱스 적용
db.store.createIndex(
{ name: 1 },
{ partialFilterExpression: { visitors: { $gt: 1000 } } }
)예제6 TLL 속성
이 인덱스 속성은 Date 타입, 혹은 Date 배열 타입의 필드에 적용 할 수 있는 속성입니다. 이 속성을 사용하여 document를 expire(만료) 시킬 수 있습니다. 즉, 추가하고 특정 시간이 지나면, document 를 컬렉션에서 제거합니다.
예제: notifiedDate 가 현재 시각과 1시간 이상 차이나면 제거
db.notifications.createIndex( { "notifiedDate": 1 }, { expireAfterSeconds: 3600 } )
document가 만료되어 제거 될 때, 시간이 아주 정확하지는 않습니다. 만료되는 document를 제거하는 thread는 매 60초마다 실행됩니다. 이점 유의해주세요.
인덱스 조회
생성된 인덱스를 조회 할 땐 getIndexes() 메소드를 사용합니다.
db.COLLECTION.getIndexes()
인덱스 제거
인덱스를 제거 할 땐 dropIndex() 메소드를 사용합니다.
db.COLLECTION.dropIndex( { KEY: 1 } )
( _id 인덱스를 제외한 ) 모든 인덱스를 제거 할 땐 dropIndexes() 메소드를 사용합니다.
마무리하며..
강좌 6편을 끝으로 MongoDB 기초 연재 강좌를 마치겠습니다. 다음 강좌부터는 팁 위주로 올리도록 하겠습니다. 감사합니다.
'Computer Science > Database' 카테고리의 다른 글
| [SQL] JOIN 조인의 정의와 종류 (0) | 2020.04.22 |
|---|---|
| Database Key 정리 (후보키, 기본키, 대체키, 슈퍼키) (0) | 2020.04.21 |
| [MongoDB] 강좌 5편 Document 수정 – update() 메소드 (0) | 2018.07.29 |
| [MongoDB] 강좌 4편 find() 메소드 활용 – sort(), limit(), skip() (0) | 2018.07.29 |
| [MongoDB] 강좌 3편 Document Query(조회) – find() 메소드 (0) | 2018.07.29 |
- Total
- Today
- Yesterday